125.彻底摆脱同步sqlalchemy
大家好~我是
米洛!
我正在从0到1打造一个开源的接口测试平台, 也在编写一套与之对应的教程,希望大家多多支持。
欢迎关注我的公众号米洛的测开日记,一起交流学习!
回顾
上一节我们review了一下代码,这一节我们来进入正轨,聊聊sqlalchemy彻底异步化。
历史问题
由于pity支持了在线编写/执行sql语句的功能,所以为了更加友好,我们特意提供了读取数据库表/字段的功能,看看下图:
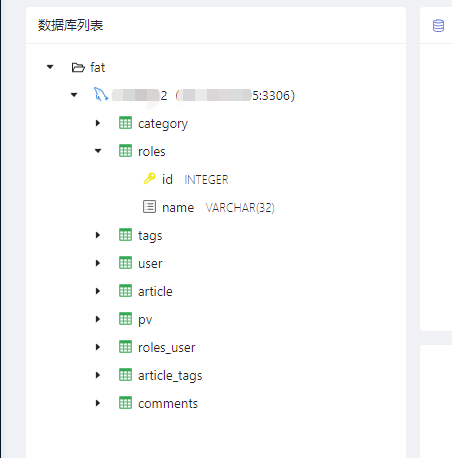
这样做的目的,并不是炫技,而是给大家一个更舒适的编写sql的环境,如果写sql的时候,数据库表和字段都给你联想了,那写起来就更轻松了。
但这么个功能呢~却不是那么好做,因为据我所知,这个功能需要用到Metadata,接着利用其的反射方法,获取到对应的表和字段信息。而异步engine又无法获取metadata相关数据,包括自动建表。
为此我一直保持着同步session和异步session混用的状态,当然这肯定不是很好的方案。
于是我今天突发奇想,还真被我找到了答案。
解决问题
具体issue: https://github.com/sqlalchemy/sqlalchemy/issues/6121
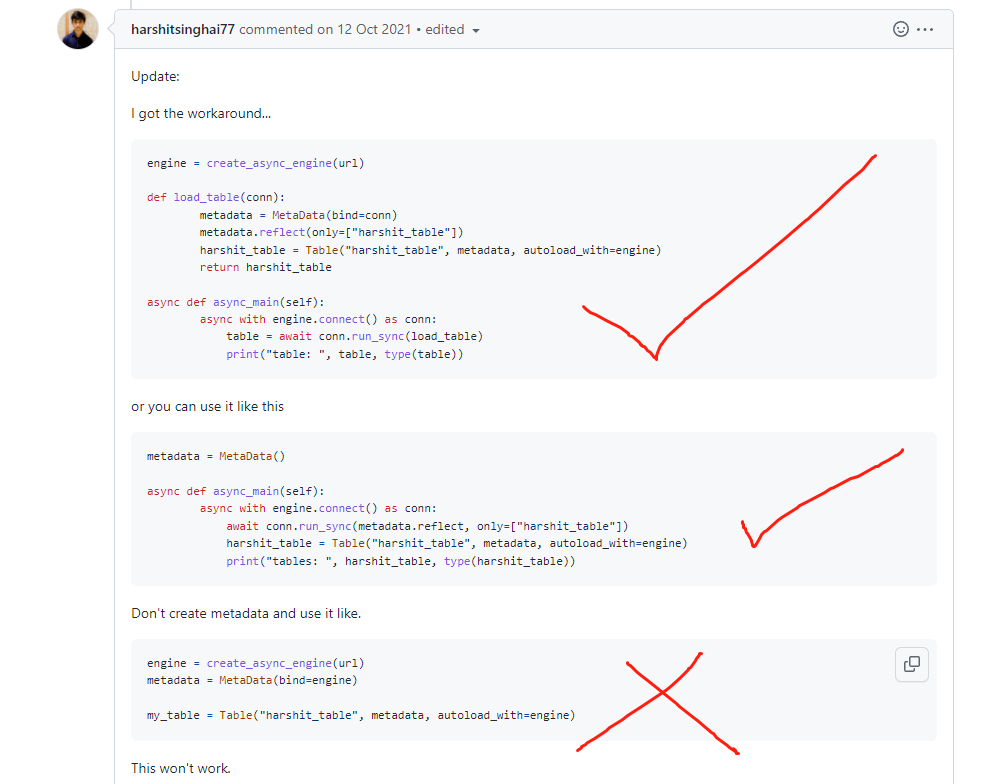
看看他的思路,其实很简单,异步engine提供了run_sync方法,这个很厉害,也就是说可以直接用异步engine去执行同步engine的方法,针对create_all(建表)+获取表信息,就很有用了,我们直接学过来,并给他一个小红心。
- 修改create_all
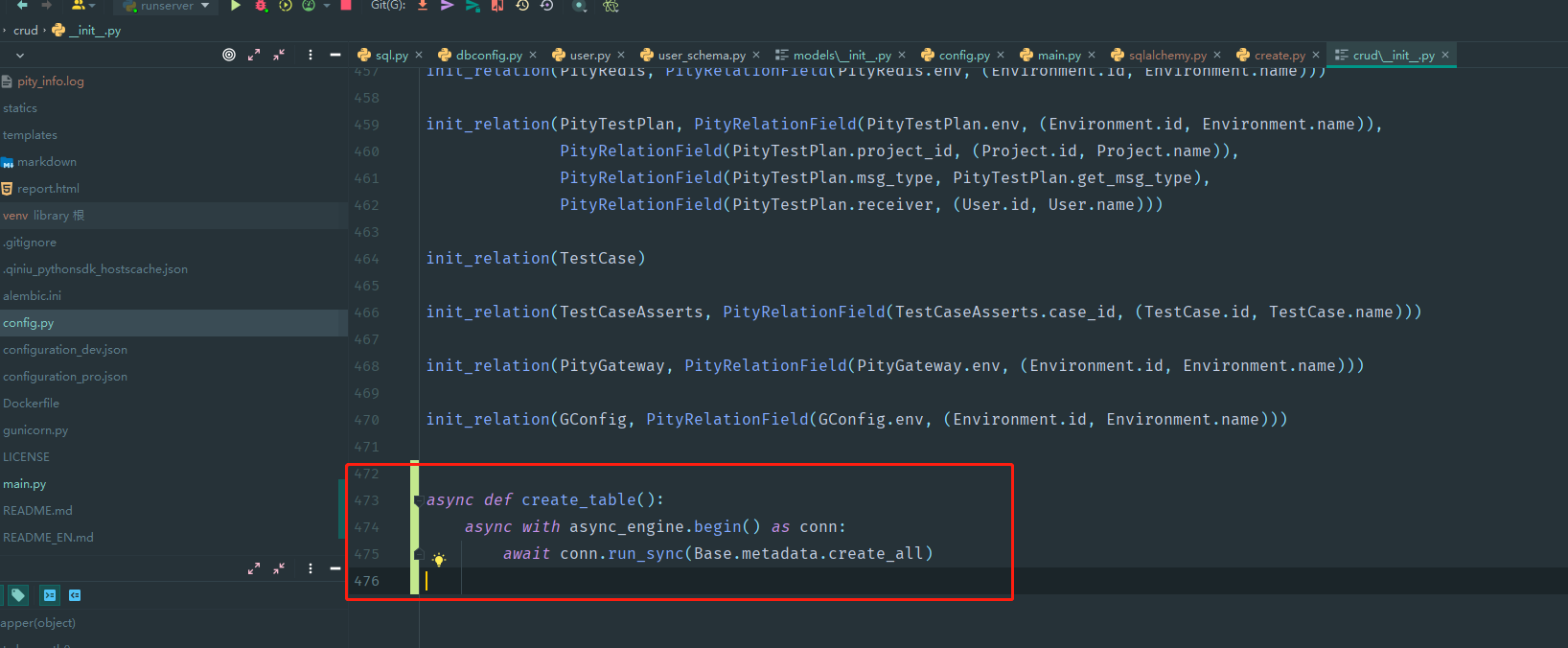
在底部定义create_table方法,由于是异步的,所以我们不能直接运行,但我们可以考虑放入startup里面,随着系统启动而执行。
- 修改main.py

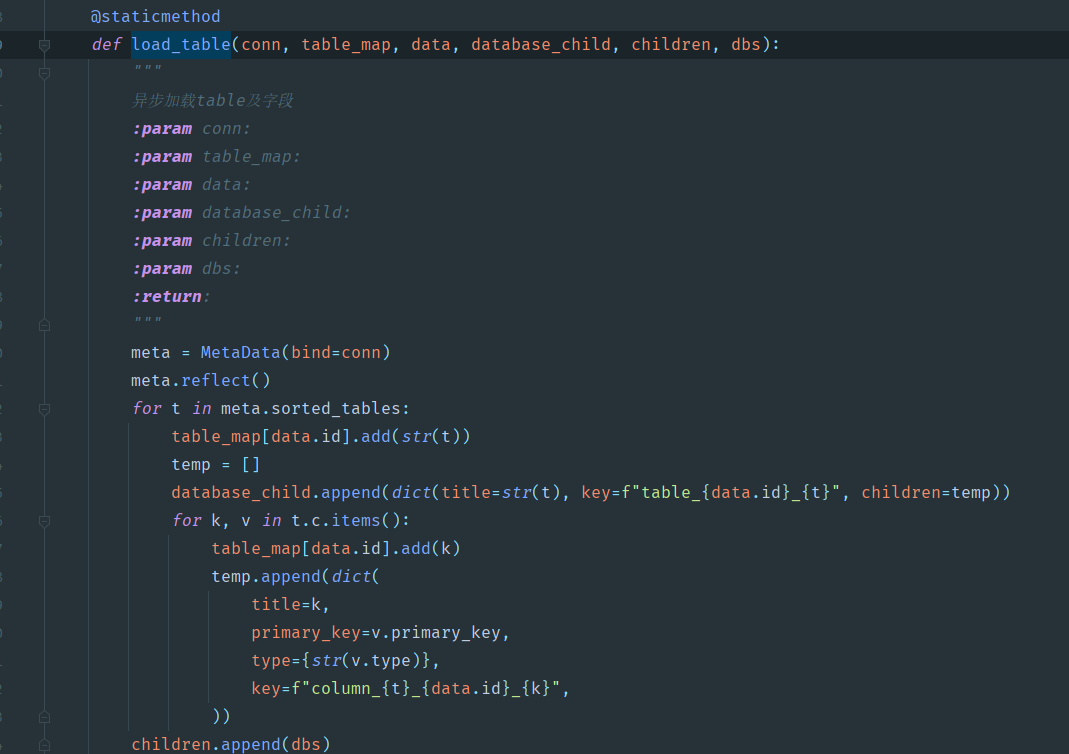
- 修改获取表的方法
先编写load_table方法,这里面由于需要展示树,所以多了很多额外的变量,核心的部分就是run_sync
- 修改调用的部分
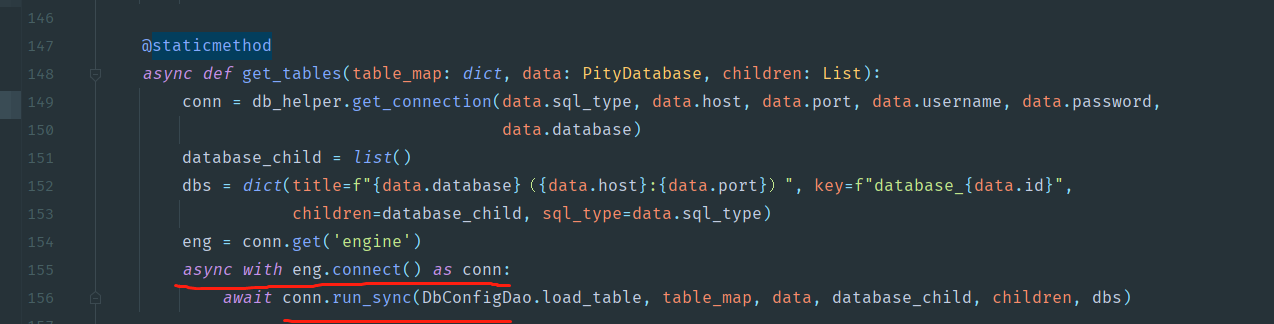
其实是把原先的逻辑,放入了一部分到table里面,好处是可以只遍历1次哦!
放心去掉mysqlconnector
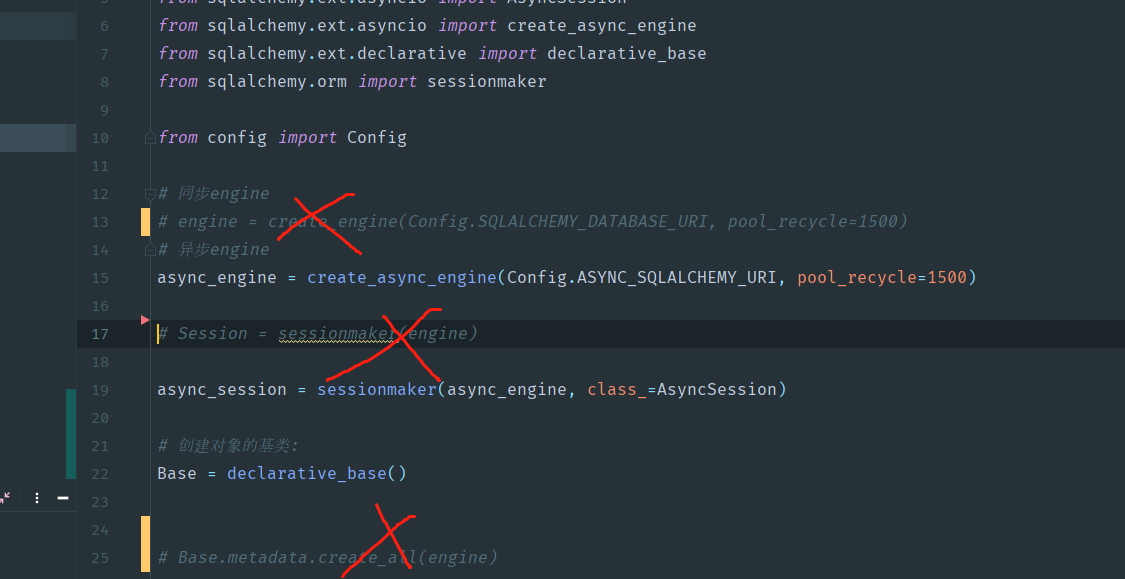
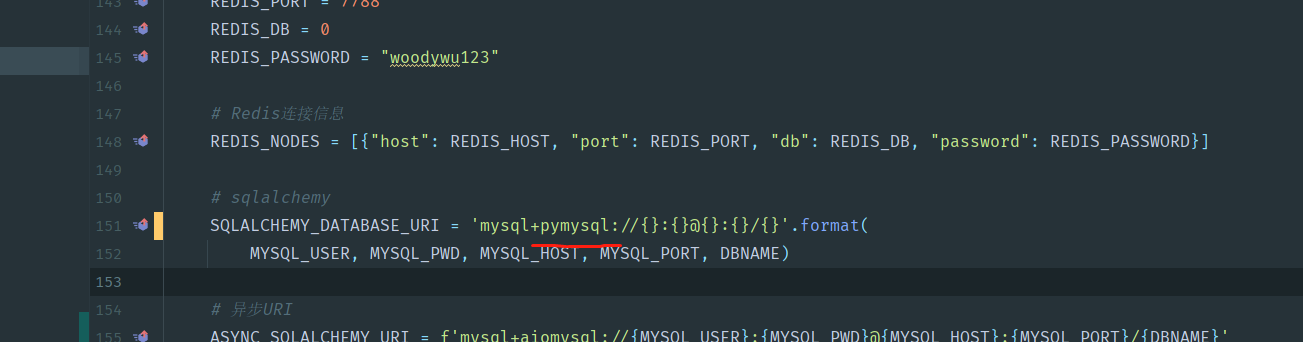
这里引擎记得改为pymysql,实在没办法,我突然想到apscheduler不支持异步session,所以这个同步session还得继续用,但我们可以只用pymysql作为驱动了(支持异步和同步),所以我们把jdbc的驱动改为pymysql。
这样来看的话,基本也是做了一个完整的清理工作,说实话,速度还可以,有点小起飞。
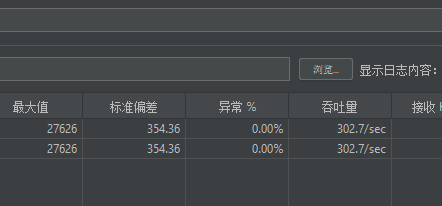
忍不住压测了一下
找了个查询网关地址的接口,其中包括了鉴权,db操作,20个线程可以到300rps,还算满意,服务也不卡,对于一个测试平台来说,这样也就够了。
无法避免的是,我花了1个多小时,把所有同步session的操作都换成了异步。
我是米洛,一直陪伴各位学习!免费的
小黄心,帮我点一个吧!