129.改造请求参数提取方式(3)
大家好~我是
米洛!
我正在从0到1打造一个开源的接口测试平台, 也在编写一套与之对应的教程,希望大家多多支持。
欢迎关注我的公众号米洛的测开日记,一起交流学习!
回顾
上一节我们编写好了curd部分,也联调了前端。这一节我们来写后端提取部分:
编写提取器父类
app/core/paramters/parser.py, 需要注意的是,我在exceptions目录定义了case相关的异常,这里import失败的话,不要惊慌,自己去定义一下吧。
import json
import random
from typing import Any
from app.excpetions.CaseParametersException import CaseParametersException
class Parser(object):
@staticmethod
def parse(source: dict, expression: str = "", idx: str = None) -> Any:
raise NotImplementedError
@staticmethod
def parse_result(data: list, match_index: str = None):
if len(data) == 0:
return "null"
# 如果是数字
length = len(data)
if match_index is not None:
if match_index.isdigit():
idx = int(match_index)
if idx >= length or idx < -length:
raise CaseParametersException(f"results length is {length}, index is not in [{-length}, {length})")
return json.dumps(data[idx], ensure_ascii=False)
if match_index.lower() == 'random':
# 随机选取
return json.dumps(random.choice(data), ensure_ascii=False)
if match_index.lower() == 'all':
return json.dumps(data, ensure_ascii=False)
raise CaseParametersException(f"invalid match index: {match_index}, not number or random")
return json.dumps(data, ensure_ascii=False)
解析器提供了一个parse方法(未实现,防止有人调用parse,直接抛出异常)。接着定义了一个默认的解析结果的方法:
由于我们采用JSONpath解析数据,而它每次返回的都是数组形式的数据,所以我们需要再次提取数据,根据用户传入的索引,这里支持random(随机)和all(所有)。
至于为什么用json.dumps(),因为我们的变量替换都采用的replace的方法,这个方法只可以对字符串进行替换,当然这里频繁地序列化/反序列化,对性能会有一定的影响,想要改善这个,我们必须得更换replace的方式。(目前还不在计划内)
可以看到,我们根据用户给的索引,也支持倒数-1这种取法,基本满足了要求。接着我们去编写JSON,kv和正则解析器(参考上上节)。
4种解析器
status_code
这种数据最为简单,我们固定取response的status_code即可。
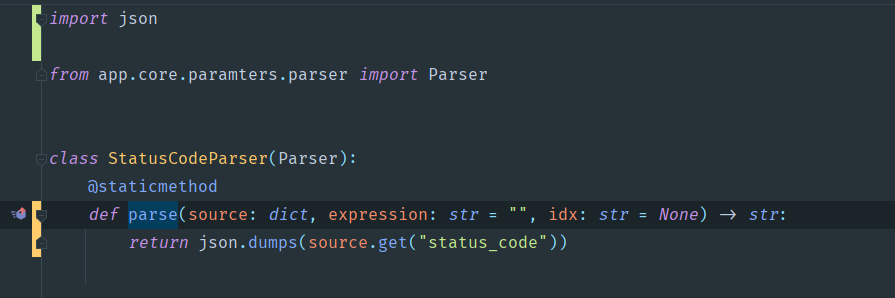
其实这里也可以直接str。
cookie/headers
import json
from typing import Any
import jsonpath
from app.core.paramters.parser import Parser
from app.excpetions.CaseParametersException import CaseParametersException
class HeaderParser(Parser):
@staticmethod
def get_source(data: dict):
return json.loads(data.get("response_headers"))
@classmethod
def parse(cls, source: dict, expression: str = "", idx: str = None) -> Any:
if not source or not expression:
raise CaseParametersException(f"parse out parameters failed, source or expression is empty")
try:
source = cls.get_source(source)
results = jsonpath.jsonpath(source, expression)
if results is False:
if not source and expression == "$..*":
# 说明想要全匹配并且没数据,直接返回data
return source
raise CaseParametersException("jsonpath match failed, please check your response or jsonpath.")
return Parser.parse_result(results, idx)
except CaseParametersException as e:
raise e
except Exception as err:
raise CaseParametersException(f"parse json data error, please check jsonpath or json: {err}")
class CookieParser(HeaderParser):
@staticmethod
def get_source(data: dict):
return json.loads(data.get("cookies"))
这里要注意点:
- jsonpath取不到数据会返回False,但对于空数组,它也取不到
所以我们要区分(空数组+全匹配)和匹配不到的情况。
regex(正则)
"""
regex for text
"""
import re
from typing import Any
from app.core.paramters.parser import Parser
from app.excpetions.CaseParametersException import CaseParametersException
class RegexParser(Parser):
@staticmethod
def parse(source: dict, expression: str = "", idx: str = None) -> Any:
try:
source = source.get("response")
if not source or not expression:
raise CaseParametersException(f"parse out parameters failed, source or expression is empty")
if idx is None:
raise CaseParametersException("index is empty, you must provide index for regex match results.")
pattern = re.compile(expression)
result = re.findall(pattern, source)
if len(result) == 0:
raise CaseParametersException(f"regex match failed, please check your regex: {expression}")
return Parser.parse_result(result, idx)
except CaseParametersException as e:
raise e
except Exception as err:
raise CaseParametersException(f"parse regex text error, please check regex or text: {err}")
不多说,就是re.match+findall。
编写解析器枚举类
from enum import IntEnum
class CaseParametersEnum(IntEnum):
TEXT = 0
JSON = 1
HEADER = 2
COOKIE = 3
STATUS_CODE = 4
编写getParser方法
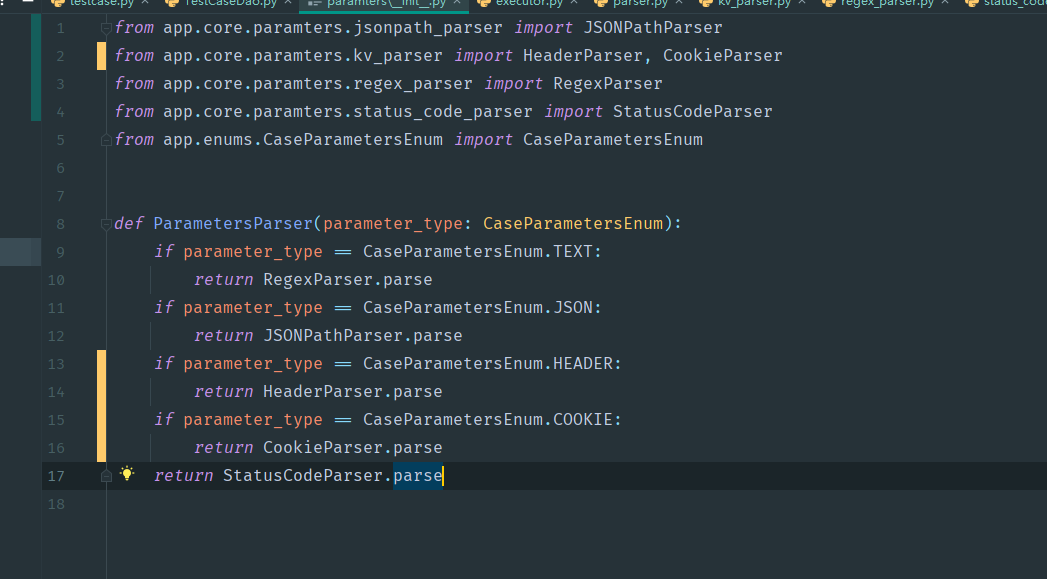
改造case执行部分
在app/core/executor.py添加以下方法:
@case_log
def extract_out_parameters(self, response_info, data: List[PityTestCaseOutParameters]):
"""提取出参数据"""
result = dict()
for d in data:
p = ParametersParser(d.source)
result[d.name] = p(response_info, d.expression, d.match_index)
return result
修改run方法:
- 获取out_parameters

- 获取后并放入params字典,替换断言/后置条件内容
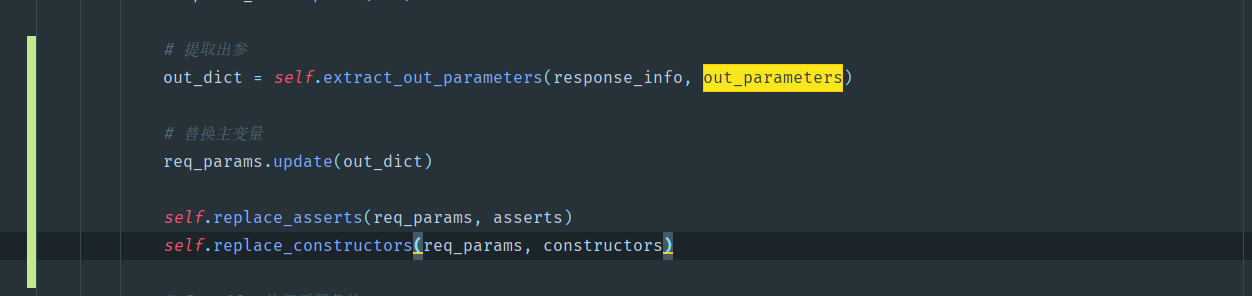
这样的话,新提取的参数,就可以在断言/后置条件使用了,我们来测试一下。
测试一下
出参是正则和状态码
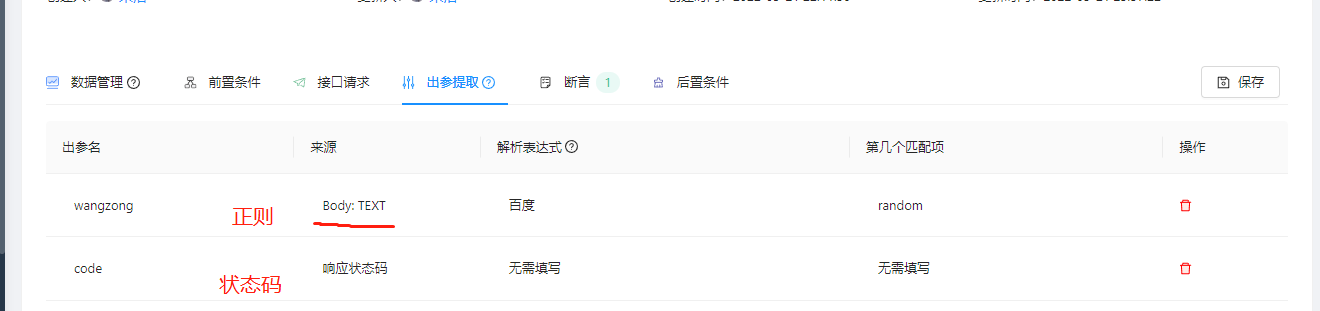
看看断言部分

如果按照预期:
- 正则+随机匹配,会查询到
百度 - code会返回200
执行下看看结果:
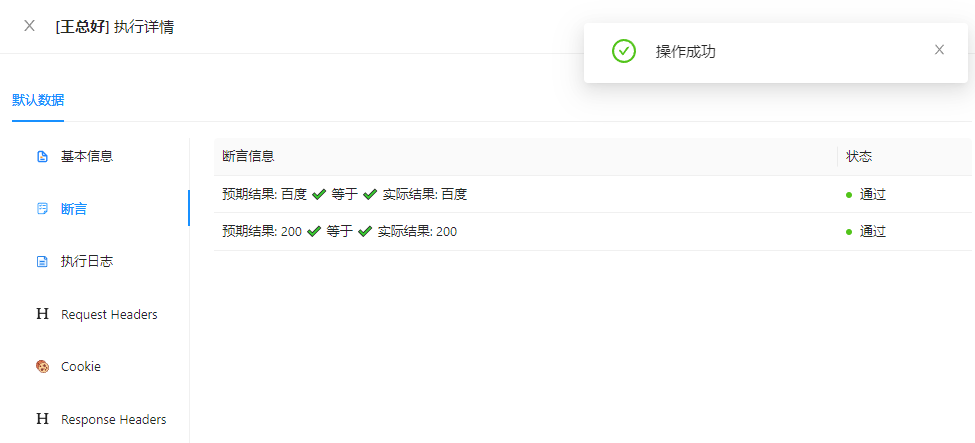
可以看到断言通过,我们来打印下返回的参数:

可以看到,正则匹配也成了,code也ok了。剩下的jsonpath我也测试过了,大家有兴趣也可以自己试试。
今天的内容就到这里了,我们下一节搞点牛逼的!开启用例录制生成之路。
我是米洛,一直陪伴各位学习!免费的
小黄心,帮我点一个吧!